
Day 3 Discussion

On day 3, we learned about the importance of trustworthy data and workflows as well as how to present case studies. In the trust-a-thon session today, we want you to investigate the data and workflow of the Severe problem and plot the predictions and observations for individual storms to identify potential biases and other issues in the model.
Please have one of your team members reply in the comments to to each of these questions after discussing them with the team. If you have not commented on the posts from the previous days, please add your thoughts there as well.
Here is the TAI4ES Severe notebook directory for reference. Revisit the training and XAI notebooks and use the modules to plot individual case studies and investigate the workflow in more detail.
Discussion prompts
- In the lecture series we presented a framework for thinking about the implications of the decisions we make throughout the AI development process. Consider the framework below and answer the following hypothetical questions about the data and workflow you’re using for the Trust-a-thon:
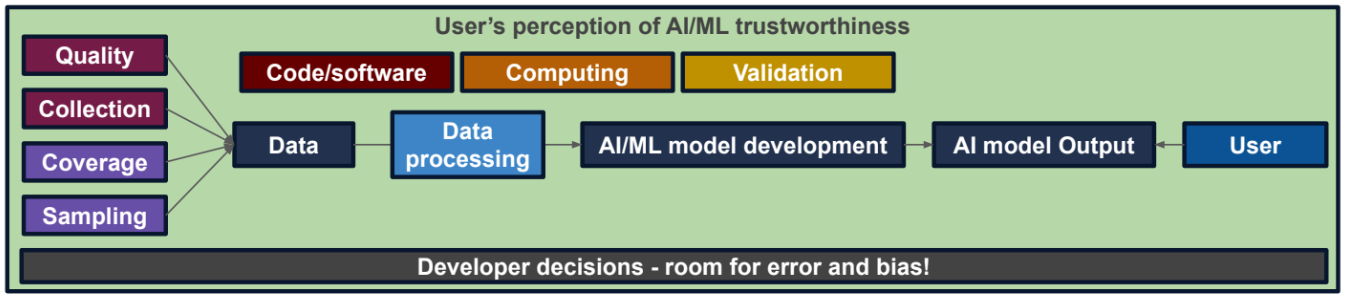
- Where in the data/data collection process do you think there was room for error and/or bias? What are the potential implications of this error and/or bias for the end user?
- Where in your workflow (as well as the workflow outlined in your assigned notebook) is there room for error and/or bias? What are the potential implications of this error and/or bias for the end user?
- How could you leverage social science and or user engagement to mitigate these issues?
- We also talked a lot about using case studies as a way to communicate about AI with end users. Outline how you would present a case study of one of your models to your specific end user. Be as specific as possible.
Question 1
1.1 Where in the data/data collection process do you think there was room for error and/or bias? What are the potential implications of this error and/or bias for the end user?
In the data collection process, satellite measurement of brightness temperature and reflectance may contain uncertainties. End users, such as the emergency manager, may be interested in how the observational uncertainties affect the model’s end results.
In addition, the representativeness of the data samples is also important. E.g., the completeness of satellite images is heavily influenced by cloud cover, which leads to non-random missing values. As a result, this error could alter the distribution of the samples and make the predictions of the models systematically biased.
1.2 Where in your workflow (as well as the workflow outlined in your assigned notebook) is there room for error and/or bias? What are the potential implications of this error and/or bias for the end user?
Errors and biases could result from model selection and the setting of hyperparameters. Different models have different strengths in learning strategies. Choosing the best setting of hyperparameters could optimize the results. We want the model to learn properly, not too specific (avoid overfitting) but also not too vague (avoid underfitting). The potential implications of this error and bias could be: that how the end user defines the loss may affect the way to model development. The loss function may change if the end user cares about different aspect of the output.
Errors could also arise from the inherent limitations of models. For example, the random forest (RF) could not extrapolate beyond the range of initial data samples. As a result, it will be unrealistic for RF models to capture peak values of the target variable. End users may not happy with the results derived by RF models if they care about the peak values the most.
1.3 How could you leverage social science and or user engagement to mitigate these issues?
We think it may be necessary to work with the end users to design a questionnaire to collect the core needs of all potential end users. Then the model verification can focus on these needs to help build trust in the models.
E.g., for errors caused by model selection, we should not choose RF for the backend of prediction. For errors caused by non-random missing values, methods dealing with imbalanced datasets should be applied to verify if the model predictions are systematically biased.
Question 2
We also talked a lot about using case studies as a way to communicate about AI with end users. Outline how you would present a case study of one of your models to your specific end user. Be as specific as possible.
We could take the emergency managers as an example. Since the emergency resources that they have are limited, they need the model to provide risk maps and the attribution of key factors to the extreme events. Bad predictions may make their efforts in vain or even have an adverse effect on further actions. Therefore, we need to show the emergency managers when will the models fail. Therefore, we need to select the worst predictions at the first stage. E.g., we could choose predictions that have the largest difference compared with the label values. Then local XAI methods could be used to calculate which features contribute the most to these values and whether they are consistent with domain knowledge. In addition, KNN could be used to find more suspicious instances. Therefore, we could show more clues about where the model will fail.
Question 1
a) Where in the data/data collection process do you think there was room for error and/or bias? What are the potential implications of this error and/or bias for the end-user?
Where in the data/data collection process do you think there was room for error and/or bias? What are the potential implications of this error and/or bias for the end-user?
The instrument used can potentially be a source of error and bias. In our discussions earlier, we saw an example where someone interfered with weather station instrumentations. This is just a single example; we have other instances where equipment fails, which can affect the quality of data leading to errors and bias in the data. When a model is trained with biased and/or inaccurate data, there is a possibility the error will be magnified, and the model accuracy will significantly be affected. The result could be disastrous if the model goes through and is applied by the end-user. Besides, the other scenario would be a complete waste of time and resources trying to correct a model that will never come close to the actual representation since it was developed using wrong data (biased and with errors)
b) Where in your workflow (as well as the workflow outlined in your assigned notebook) is there room for error and/or bias? What are the potential implications of this error and/or bias for the end-user?
We believe errors and bias can stem from anywhere within the workflow. A slight mistake in any process, be it data collection, sampling, processing, developing the AI model, or training the model, can affect the final model’s trustworthiness. It is therefore essential to cross-check and validate every step to minimize the chances of accumulating errors and bias. An error in one step affects the following process, which leads to error accumulation. Some potential implication of this to the end-user is mistrust of the model, as there is a high chance the model will not perform effectively. Particularly in the case study of Severe, errors or biases in the data could occur when it is resampled to reduce its size. As this process is carried out, the technique may induce changes in the information, possibly not considering some events or even occurring to overestimate the number of events.
c) How could you leverage social science and or user engagement to mitigate these issues?
Social science and user engagement help the AI model developer understand some of the end user’s expectations. It is possible to develop a model that will not be adopted simply because it does not meet the end-user expectations. Besides, social science also helps understand the tools used to serve a similar task the model will help with. This is important as you can have that in mind when creating the AI model and even develop a case study to evaluate the performance of the existing tools against your newly developed AI model. If the built model has significant improvements and factors in the end-user expectations, there is a high chance that the model will gain more trust and be quickly adopted by the end-user.
Question 2
We also talked a lot about using case studies as a way to communicate about AI with end-users. Outline how you would present a case study of one of your models to your specific end-user. Be as specific as possible.
When presenting a model to the end-user, it is essential to be as detailed as possible. In our case, we are developing a model that can predict lightning flashes likely to cause a wildfire to the risk manager. To depict the viability and applicability of our model, we will work closely with our end-user. Our initial goal is to establish a platform where we can get feedback from our end-user and present some case studies for their feedback. This feedback will give us a better understanding of what specific issues the user wants or expects the model to address. In our final presentation, we will highlight the model’s best performance and limitations by presenting case studies on best hits and worst misses. It would be essential to show a case where a false positive triggered a reaction of the warning systems. Using XAI methods, hypotheses can be developed about what conditions led to this false alarm. By putting the situation in context, and even taking advantage of the experience of the fire warning systems, a better interpretation of the results of the XAI methods can be made and lead to possible improvements to the model. This same strategy can also be used for cases where false negatives have occurred.